
Models are crying out for high-quality, domain-specific data to become specialised, but it’s not always bountiful. Couple that with concerns over privacy or bias, and there’s not always a lot of data left to train and test AI.
For example, it can be difficult to model for rare illnesses when they are especially sparse as a proportion of the general population. Or we may wish to model weather events, and extreme weather records may be insufficiently represented in real-world datasets. That’s why generating synthetic data is central to modern machine learning.
But poorly generated synthetic data can introduce unrealistic patterns and distributions within the data. Until now, it has faced a trade-off between diversity of data and factual accuracy. The good news is that FLock.io has just released two new papers detailing research into a method that generates artificial data that actually outperforms the original raw data when used for model training.
Both papers tackled the same core problem: the challenge of directly turning raw data into high-quality training data. We have developed an algorithm approach that takes us a step closer to solving it. It has fewer hallucinations and better reliability, generating data that outperforms the original raw data for training models.
- “CircuitSynth: Reliable Synthetic Data Generation”, accepted into ACL 2026 Findings.
- “GraphSynth: Resolving the Diversity-Reliability Trade-off with Probabilistic Factor Graphs”, accepted into the ACL 2026 MainConference.
As an AI research and infrastructure company, this is far from our first paper. Check out our other academic projects here. For example, earlier this year we demonstrated a dynamic buyback-and-burn mechanism stabilises token value in decentralised AI economies
[ 👋 Hi there! If you’re here to find out more about FLock.io, follow us on X, read our docs, sign up to AI Arena and check out FOMO. Email us at hello@flock.io.]
Why synthetically generate data, and what are the challenges?
Synthetic data generation is the process of creating artificial datasets using algorithms, simulation or generative AI. This allows the training of AI models when data is scarce or when bias or privacy concerns in sectors like finance or healthcare prevent the use of real-world data. It ensures it mimics the patterns and relationships of original data without containing private information – it does not contain personally identifiable information (PIII), allowing for safer data sharing and testing.
However, synthetic data comes with downsides. LLMs are frequently struck by hallucinations and logical inconsistencies. They can suffer mode collapse: when the model increasingly ends up generating monotonous, bland and repetitive output, learning only from synthetic outputs instead of the full breadth of the training data. Existing approaches, like prompting or retrieval-augmented generation (RAG), lack the mechanisms needed to balance linguistic expressivity with guarantees.
LLMs are the de facto engines for synthetic data generation, offering a scalable solution to data scarcity in domains ranging from software engineering to biomedicine. However, the utility of this synthetic data is capped by a critical tension between generative diversity and factual reliability. In high-stakes applications, where data must be not only diverse but also strictly factual and structurally valid, the unconstrained nature of standard LLM generation poses an unacceptable risk of propagating errors and model collapse.
A central challenge in generating high-quality synthetic data lies in accurately modelling the topology of the semantic space. Real-world knowledge is inherently polyhierarchical and interconnected; concepts often belong to multiple overlapping categories simultaneously (e.g. “viral pneumonia” is both an "infectious disease” and a “respiratory condition”). However, prevailing structured generation frameworks enforce a rigid tree topology that recursively partitions space into mutually exclusive leaves. RAG provides factual context but lacks the mechanisms to enforce logical consistency.
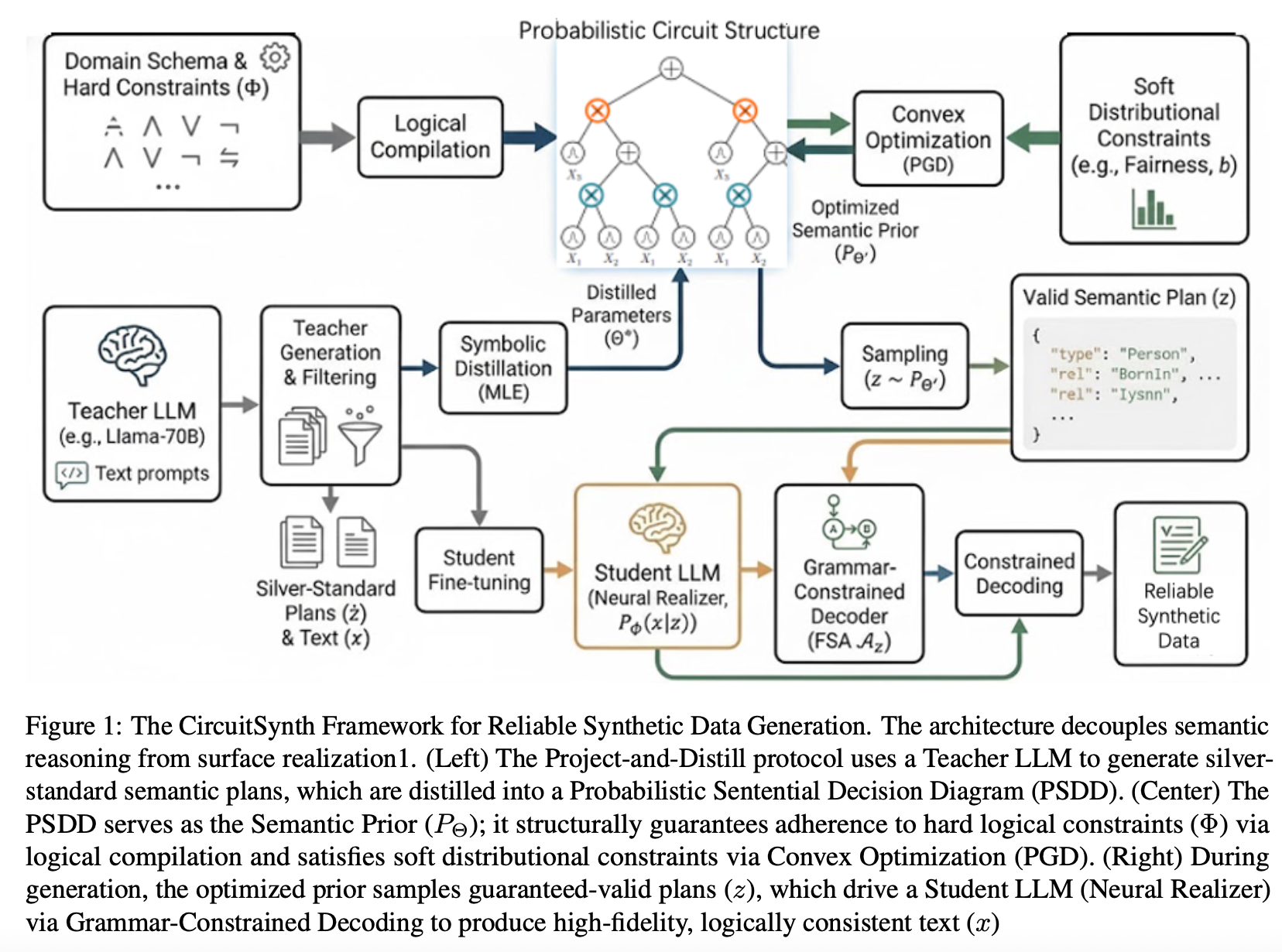
CircuitSynth decouples semantic reasoning from linguistic generation
CircuitSynth is a neuro-symbolic framework that explicitly decouples semantic reasoning from linguistic generation by utilising a Probabilistic Sentential Decision Diagram (PSDD) as a tractable semantic prior.
CircuitSynth guarantees 100% schema validity through a Logical Compilation process, even in complex logic puzzles where unconstrained baselines fail (12.4%). It embeds hard constraints directly into the circuit’s topology, rendering invalid states mathematically impossible. To prevent mode collapse, the framework employs convex optimisation to strictly enforce soft distributional constraints, such as fairness and rare attribute coverage, directly on the circuit’s parameters. It significantly outperforming state-of-the-art methods in rare-combination coverage.
The Project-and-Distill training protocol leverages a Teacher LLM to induce valid semantic plans, enabling the model to outperform state-of-the-art baselines on complex logical benchmarks.
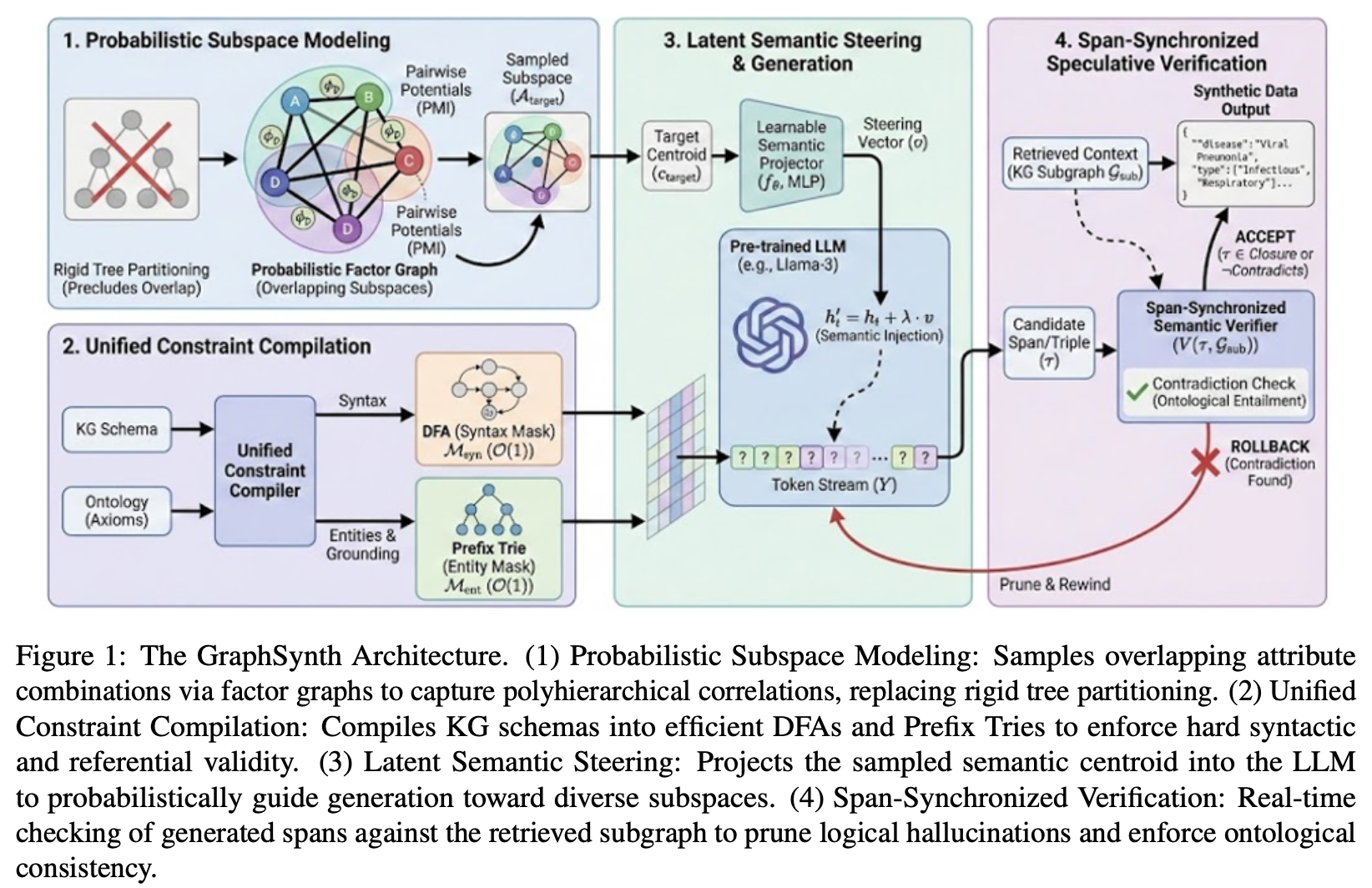
GraphSynth is a KG-guided probabilistic subspace generation framework
Subspace-based partitioning methods, while improving diversity over unconstrained generation, cannot capture the overlapping attribute combinations essential for realistic data distributions. On the constraint side, automata-based methods focus exclusively on syn- tax, leaving semantic correctness to chance. Mean- while, retrieval-based methods rely on soft guidance via prompts, which LLMs of- ten override, leading to plausible but hallucinated content.
Consequently, there remains a significant gap where we lack a unified framework that can synthesise data across flexible, graph-structured subspaces while simultaneously enforcing rigorous syntactic validity and hard semantic boundaries.
We propose GraphSynth: a KG-guided probabilistic subspace generation framework. We replace the rigid tree topology with a flexible factor graph that explicitly models the overlapping nature of attributes using pairwise potentials derived from Pointwise Mutual Information (PMI).
This allows us to sample complex, multi-attribute subspaces that respect the true correlations of the domain. To enforce reliability, we introduce a unified constraint mapping mechanism that translates high-level KG schemas into low-level deterministic finite automata for hard structural masking, coupled with a token-level semantic verifier that utilises retrieved context to prune factually inconsistent paths in real-time. This approach naturally unifies the structural guarantees of formal methods with the semantic richness of knowledge graphs.
Our primary contributions are:
- Overlapping subspace generalisation via factor graphs
- Unified constraint compilation
- Knowledge-constrained decoding
More about FLock.io
FLock.io is an AI research and infrastructure company pioneering enterprise-grade federated learning and distributed AI solutions. Its decentralised federated learning architecture and production-ready platforms (AI Arena, FL Alliance, and FLock API Platform) enable organisations to train and deploy their own custom AI models on local hardware while maintaining full data privacy, model ownership, and regulatory alignment by design.





