FLock: Federated Machine Learning on Blockchain
Democratising AI through Decentralisation of Data, Computation, and Models
Abstract
The rapid pace of AI development has highlighted significant challenges in its creation and deployment, primarily due to the centralised control maintained by a few large corporations. Such an approach exacerbates biases within AI models due to a lack of effective governance and oversight. Furthermore, it diminishes public engagement and raises serious data protection concerns. The resulting monopolistic control over data and model outputs also poses a threat to innovation and equitable data usage, as users unknowingly contribute to data sets that serve the interests of these corporations.
FLock democratises AI development and alignment through on-chain incentive mechanisms. By promoting open source development and data ownership, FLock facilitates an open and collaborative environment where participants can contribute models, data, and computing resources with rewards determined by on-chain consensus. This approach improves transparency and collaboration at scale without introducing biases from centralised entities. Ultimately, FLock enables diverse communities to develop purpose-built AI models, offering bespoke solutions tailored to their specific needs, revolutionising the landscape of AI development and deployment.
I. Introduction
Spanning all fields, collaboration has historically catalysed innovation. This is manifest in the case of the scientific and the digital. By pooling collective expertise, we have forged disruptive solutions at speed. At present, this ideal faces barriers when applied to AI development and deployment: notably, diminished public engagement, pervasive concerns regarding concentrated control, and data protection exerted by a handful of corporations. Meanwhile, blockchain technology[1][2]has demonstrated its efficacy in multiple areas needing distributed corporations, such as decentralized finance[3], voting and governance. Research into and deployment of blockchain to transform AI development is now underway.
FLock, predicated on community involvement and a staunch commitment to data protection, is poised to spearhead the democratisation of AI ecosystem by using blockchain.
A. The Problems with Centralised Control over AI Creation
In the present day, the primary obstacle to innovation in the realm of AI is its centralised control. This centralised structure mandates that all AI training, decision-making processes, and data storage are controlled within a single entity or location[4]. This results in the following pitfalls:
- Single Point of Failure: Vulnerability to disruptions from technical issues and cyberattacks.
- Value Plurality: Lack of value plurality means biases of single entities are reflected in AI. With centralised institutions exerting absolute control over models[1][2], the values of the output models are also centralised[3]. For instance, the world reimagined by Google's generative AI tool, Gemini, is widely criticised[4].
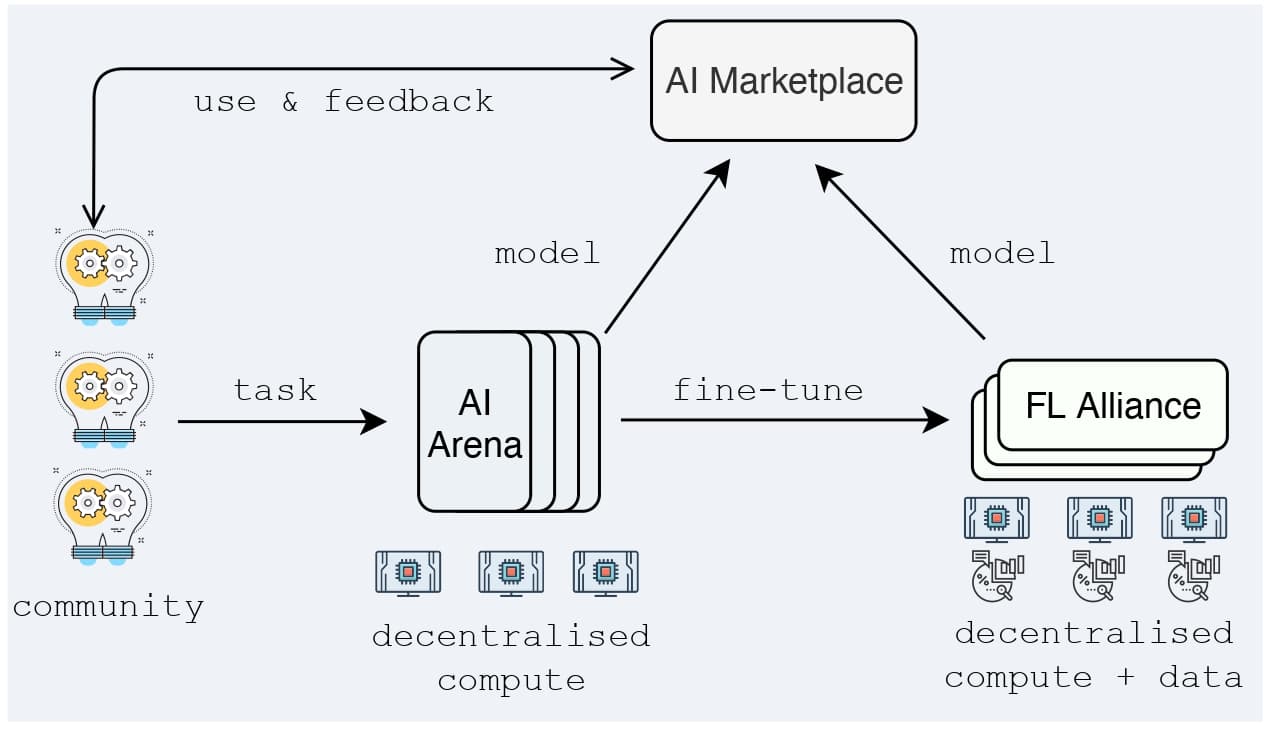
FIG. 1: FLock System Logic. Upon a task creation, the model is first trained and validated in AI Arena, a blockchain-based decentralised training platform, and then optionally further fine-tuned in FL Alliance using participants' local data. Finally, the model is deployed by applications in the AI Marketplace, where feedback will be used to further improve the model. - Data Protection: Providers of closed-source LLMs[5], such as OpenAI, have the capability to monitor all user interactions with their models, thereby raising significant data protection concerns. In addition, under this centralised framework, every user who interacts with a LLM becomes an unwitting contributor of data to these vast corporations that maintain ownership of the models. There is a pressing need to enhance the fairness of contribution incentives and to more accurately assess the value of user-contributed data.
- Governance: Recent research[6][7][8]has highlighted a concerning trend in which the lack of governance has led to a pronounced exacerbation of biases and inaccuracies within the models.
- Scalability: As the volume of data and complexity of tasks increase, limited processing power acts as a bottleneck.
- Innovation: Progress is stifled in an environment where a limited number of entities have the means to experiment.
B. FLock Solution
FLock[13][14] is a blockchain-based platform for decentralised AI. As shown in Figure 1 and Figure 2, FLock eliminates obstacles that prevent active participation in AI systems, empowering communities to contribute models, data, or computing computing resources in a modular and decentralised way. AI models can be trained and validated in AI Arena and further refined in Federated Learning (FL) Alliance. Harnessing blockchain technology, FLock introduces incentive mechanisms for participants, fostering a collaborative environment. This results in the development of a wide range of purpose-built models, created by, with, and for the communities, offering tailored solutions to meet specific needs.
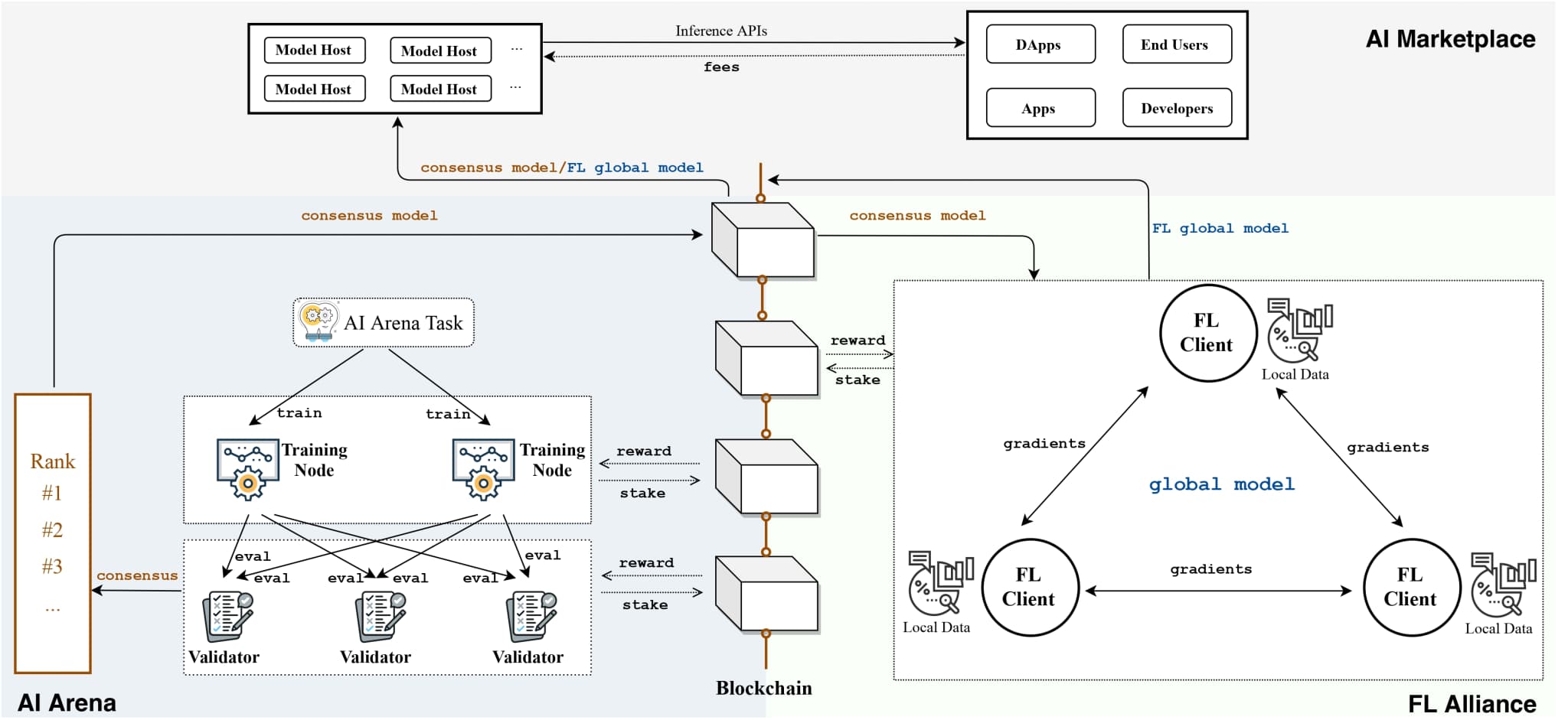
II. FLock System Overview
The FLock system consists of the blockchain layer, AI layer, and various participants. Each component plays an essential role in ensuring the system's functionality and security.
A. Blockchain Layer
FLock's tokenomics incorporates a blockchain-based reward mechanism designed to enhance resilience against malicious user attacks. This robust security feature is underpinned by a carefully designed incentive mechanism. The blockchain layer acts as the foundation for both stakeholder participation and the distribution of rewards. This layer employs smart contracts to ensure that participants can securely lock in their stakes, fostering an environment of trust and transparency. The process is designed to incentivise participation by allocating rewards based on contributions, thus encouraging a more engaged and active community. The blockchain layer's inherent security features safeguard against fraudulent activities, ensuring uncompromised integrity of staking and reward distribution. It is an critical component to support the model safety and improve resilience against malicious user attacks. By leveraging smart contracts, the system automates an efficient and fair rewards process. Automation reduces human error and ensures that rewards are distributed in a timely and fair manner.
B. AI Layer
The AI layer offers infrastructure for decentralised training, extracting and monetising knowledge from data. It encourages compute and data contributions from the community, using blockchain for rewards based on thier contributions.
- AI Arena. AI layer supports a conventional machine learning (ML) model training paradigm, optimising models directly on users' devices with their own or public data. To maximise the generalisation ability and performance of the final trained models, this layer is designed to encourage community members to contribute various public or local data, harnessing the broader community's power. By leveraging blockchain, it ensures contributors are continually engaged and rewarded based on the quantifiable impact of their data on improving the models.
- FL Alliance. Utilising the FL[15] approach, the AI layer enables thousands of participants to collaboratively train a global model, where data sovereignty is preserved by ensuring that no local data are transmitted at any stage of the training process. Within the AI layer, a model aggregation component allows participants to upload weights from models trained on their unique local data. These weights are then aggregated to build an optimal global model, enhancing its generalisation capabilities and performance. The integration of training task automation and deployment orchestration components simplifies the process for users to join tasks and contribute valuable knowledge extracted from their data.
In FLock, AI Arena tasks will engage participants from the Web2 AI community, who possess the necessary computational resources to train and validate models using publicly available datasets. These trained models can be further refined through FL Alliance tasks, which draw in participants capable of contributing their own local data.
C. AI Marketplace
Once models are trained and fine-tuned through AI Arena and FL Alliance, they can be hosted on our platform. This platform serves as a comprehensive environment for deploying ML models, making them accessible within blockchain networks of virtual machines (VMs). By integrating with these networks, the platform facilitates the seamless execution and inference of complex ML models, providing real-time, scalable, and secure solutions.
The infrastructure for model management includes version control, model monitoring, and automated updates, ensuring that the models remain accurate and efficient over time. It can provide inference APIs or SDKs that developers can use to integrate these models into their applications.
Model hosts are compensated based on the quality and frequency of their contributions. They play a crucial role in generating inferences and maintaining the infrastructure.
D. Participants
There are various categories of participants in FLock.
- Task Creators: Task creators will define the training tasks. Any participant who is willing to stake sufficient assets into the system or has already contributed to the system can potentially be selected as a task creator. This broadens the range of stakeholders, conferring a sense of ownership and active involvement.
- Training Nodes: Training nodes compete in AI task training and are required to stake tokens to be eligible. This requirement ensures a commitment to the network's integrity and facilitates a distributed, trust-based mechanism for task assignment. This stake acts both as a gatekeeper to maintain a high standard and as a foundational element in the network's security protocol, ensuring that nodes have a vested interest in proper execution and the overall health of the ecosystem.
- Validators: Validators are responsible for evaluating work done by training nodes, submitting validation scores that influence reward distribution. They participate by staking tokens, which grants them the opportunity to validate tasks assigned to them, ensuring hardware compatibility and fair task distribution proportional to their stake. Upon completion of a task, they can withdraw their stake and claim rewards, which are calculated based on their performance and adherence to the expected outcomes. The design ensures that validators are incentivized to provide accurate and honest validations, thereby maintaining the quality and reliability of the network's computational tasks.
- Delegators: Delegators contribute to the FLock system by supporting other participants’ staking process, enhanc- ing the network’s validation capacity without directly participating in the task training or validation process. Delegators share in the rewards earned by their associated delegatees, based on predefined algorithms that account for their staked contribution. Note that training nodes and validators who choose to accept delegation are free to choose a reward share ratio. The higher the ratio, the bigger the reward share their delegators will receive. The role of delegators allows individuals to participate in the network’s training, validation and economic activities, leveraging their tokens to support delegatees, without needing the technical capabilities to train or validate tasks themselves.
- FL Clients: With a FL framework, FL clients will contribute their local data to enhance the model trained for the AI Arena task. In each FL task, participants will be randomly designated as either proposers or voters. Proposers will be tasked with training the model within a FL framework, while voters will assess the training outcomes produced by the proposers. Both proposers and voters will receive rewards or face penalties based on their respective performances. FLock ensures that all participants are motivated to contribute effectively to the overall model improvement.
- Model Hosts: The role of a model host in AI Marketplace involves deploying and managing trained models, providing infrastructure for secure and scalable execution, and enabling access through APIs and SDKs. The host ensures the models are kept up-to-date, monitors their performance, and facilitates integration into applications. Additionally, they will be compensated for their contributions to generating inferences and maintaining the system's integrity.
III. FLock Tokenomics
FLock aims to build a fair and incentive-compatible ecosystem, designed to foster collaboration and ensure long-term alignment within its community. This vision is realised through a strategically designed reward allocation system, an effective slashing mechanism for accountability, and the cultivation of active token demand.
A. Token Supply
- Emission: FLock's ecosystem will feature
$FLOCK1 tokens, set to be distributed to various stakeholders through an initial token emission and a strategically designed reward allocation system over time. Participants will receive rewards in$FLOCKtokens based on their contributions to the system. Participants in the FLock system, such as training nodes and validators, are required to contribute computing or storage resources to complete model training and validation in order to receive rewards. This means that the value of the$FLOCKtoken will, at a minimum, correspond to the value of the resources consumed during these processes. - Slash: FLock robust mechanisms ensure the integrity and reliability of the system by penalising participants that engage in malicious activities. In AI Arena, if a participant is identified as acting against the system’s rules or attempting to undermine the system through malicious actions, they are subjected to “slashing”. Slashed tokens will be rewarded to the honest participants. Slashing protects the system from immedi- ate threats by disincentivising malicious actors and reinforces a culture of trust and cooperation among participants.
B. Token Demand
Active token demand is encouraged through multifaceted approachs as follows, showing the value of circulating tokens within the ecosystem.
- Utility: Participants are required to stake
$FLOCKto play a role. This reflects their vested interest in the integrity and success of operations. For task creators facing urgent needs to gather top-notch trainers for their model training or operating under tight deadlines, they may opt to pay additional$FLOCKas bounties. These bounties will then be distributed as payments to participants involved in those specific tasks to prioritize the training processes. Participants can be also supported by delegators through$FLOCKtoken delegation. By doing so, the system boosts the participants' stake within the FLock system and incentivises a symbiotic relationship. Delegators, in turn, earn a share of the rewards earned by their participants, fostering a competitive environment where participants are motivated to offer attractive terms to potential delegators. - Payment: Community members are able to access and utilise winning models which are trained and fine-tuned in AI Arena and FL Alliance, and hosted on AI Marketplace. End users enjoy rate limit in their access to such models based on their stake amount, beyond which they will be charged in
$FLOCKas payment. On the other hand, model hosts need to stake$FLOCKin order to host winning models. They are able to customise whether and how to charge end users of these models. At inception phase, model hosts will receive part of the daily emission in order to incentivise their participation. Yet such incentives are expected to diminish over time. Overall, such design creates a such design creates a sustainable and competitive environment in which demand and supply for cutting- edge models are dynamically balanced, fostering innovation and ensuring that the latest advancements continue to meet the evolving needs of the market. The payment mechanism also creates a non-negligible financial barrier in access to our models, thus helps mitigate potential DoS attacks from malicious participants. - Governance Participation: Holding
$FLOCKtokens grants members the power to influence the network's future through participation in the Decentralised Autonomous Organisation(DAO) governance. This not only decentralises decision-making but also adds a layer of utility and value to the tokens, as they become a key to shaping the ecosystem's development.
IV. FLock Incentive and Security
A. Incentive
FLock leverages well-designed incentive mechanisms to reward participants. The distribution of newly emitted tokens is carefully orchestrated across AI Arena Task tasks and FL Alliance tasks, reflecting a strategic allocation that hinges on the staking dynamics within each task category.
In our system, verified tasks are granted a share of daily rewards, serving as an incentive to foster the growth of the task creation ecosystem. This reward distribution is intentionally restricted to tasks approved by the DAO to safeguard the protocol from being exploited by low-quality or malicious tasks that could otherwise drain emissions without contributing meaningful value.
Each newly created AI Arena and FL Alliance task has the option to undergo a verification process conducted by the community-led DAO. This process is designed to ensure that tasks meet the necessary standards of quality and alignment with the ecosystem's goals. Once a task successfully passes verification, it becomes eligible for $FLOCK's daily emissions, providing the task creator with additional resources to incentivize participation and collaboration.
On the other hand, if a task is created permissionlessly without the FLock DAO’s verification, the responsibility falls on the task creator to self-fund the task. This involves using their own $FLOCK to cover the costs associated with reward allocations for various participants. While this route allows for greater flexibility and decentralization in task creation, it also places the financial burden of supporting the task’s ecosystem on the creator. This mechanism is designed to balance innovation with quality control, ensuring that only well-constructed tasks benefit from community-supported rewards while still allowing for creative freedom in the ecosystem.
In the long run, this dual approach aims to encourage high-quality task creation, foster a vibrant and trustworthy ecosystem, and maintain the integrity of the $FLOCK reward system by aligning incentives with the community’s standards and goals.
Once tasks are created, the distribution of rewards between DAO-verified AI Arena and FL Alliance tasks is dependent on the their relative stake amount of active tasks. As such, the rewards of $FLOCK allocated to all active AI Arena tasks will be:
and for all active FL Alliance tasks:
$FLOCK,
| Attacks | Description | FLock Mitigation |
|---|---|---|
| Sybil Attacks | An attacker might gain disproportionate influence in the FLock system by creating and controlling multiple fake identities of participants. |
|
| DoS Attacks | An attacker might exhaust the FLock system resource and make it unavailable to honest participants. |
|
| Free-rider Attacks | Free riders benefit from a system without contributing fairly. In the FLock system, a free rider training node may randomly submit models without actually training. Similarly, free rider validators give random scores instead of honestly evaluating models. |
|
| Lookup Attacks | Training nodes could cheat by learning to predict past validation score calculations. |
|
| FL Model Poisoning Attacks | In FL Alliance, an attacker may use biased or corrupted data during the training process to degrade the model's performance. |
|
Note that at the initial phase, to incentivise participation, task creators will also receive a slice of the reward pool. This reward, however, is expected to be phased out over time.
In AI Arena, this allocation is meticulously calculated based on the aggregate staking contributions from task creators, training nodes, validators, and delegators for each task.
Rewards among AI Arena Tasks: Within the span of a single day, consider the situation where there are AI Arena tasks with the total staking amounts of . The total staking amount, , includes the stakes from all participants involved in this task. This means that the stakes from any type of user will influence the reward distribution among tasks. is a system parameter that can be adjusted via DAO decision.
Assume the amount of daily emitted
$FLOCKtoken is . For an AI Arena task with the total staking amount of , its daily total rewards is:For each AI Arena task, rewards are allocated among task creators, training nodes, validators, and delegators. In the initial version of FLock, if a validator has delegators, of their rewards are designated for these delegators. It is important to note that this distribution parameter is flexible and subject to adjustments through the FLock DAO governance.
Rewards among FL Alliance Tasks: An FL Alliance task should be derived from a finished AI Arena task to be further fine-tuned. The initiation of an FL Alliance task automatically triggers the creation of a new FL contract.
For each active FL Alliance task within the ecosystem, daily rewards are transferred to the respective FL smart contract, provided the task is still in progress and has not surpassed its maximum allotted lifecycle. This preliminary step ensures that the rewards are earmarked and protected for participants actively engaged in the task. Subsequently, upon meeting the predefined conditions, the FL smart contract autonomously distributes the rewards to the participants, according to their contributions.
B. Security
As shown in Table I, the FLock system's security is designed to be resilient against attacks.
Sybil attacks are mitigated by a requirement to stake a minimum amount of assets, making it costly to control multiple identities. Validators are kept unaware of the model origins, reducing the risk of collusion. Only the top-performing training nodes and validators receive rewards, discouraging poor performance and manipulation. To mitigate DoS attacks, the system implements rate limiting, preventing any single participant from monopolising resources. Free-rider attacks are addressed by rewarding only the top contributors, ensuring that participants who do not genuinely contribute cannot benefit. The use of dual datasets (Dataset A and B) in evaluations prevents lookup attacks, as optimising for one dataset does not guarantee success in the other. For FL model poisoning attacks, a majority voting system and slashing mechanism protect the model’s integrity, punishing malicious actors and discouraging future attempts. These measures collectively fortify FLock against a range of threats, promoting a secure and reliable decentralised training environment for participants.
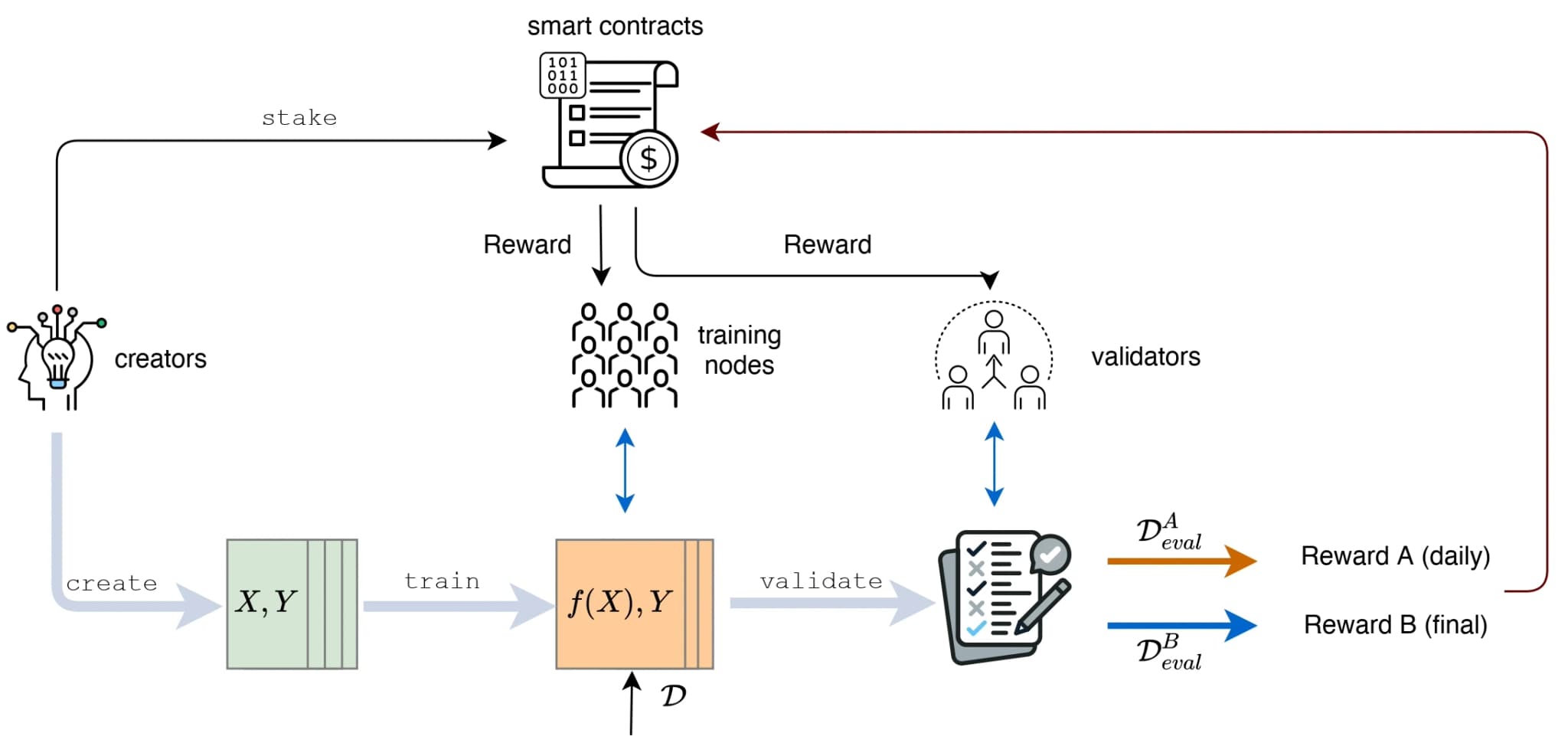
V. FLock Consensus in AI Arena
Figure 3 shows the overview of the workflow of a FLock AI Arena task.
A. Task Creators
Task creation is the primary stage of the training cycle. Creators define the desired models and submit tasks to the platform. Anyone who satisfies the criteria is eligible to be a task creator, making the system inherently democratic and accessible to a wide range of stakeholders. This inclusivity fosters a sense of ownership and active involvement within the FLock community.
To qualify as a task creator, users must meet one or more of the following criteria:
- Stake a sufficient amount of
$FLOCK. - Have successfully trained or validated a task previously, as evidenced by on-chain records.
- Possess a reputation in the ML space or be recognised as a domain expert in relevant fields, as verified by the FLock community.
If the task creator and the created task are verified by the FLock DAO, the task will be eligible for daily $FLOCK emissions. However, if the task creator chooses not to undergo verification by the community-led DAO, they must self-fund the task using $FLOCK to cover the costs associated with reward allocations for the participants.
In addition to gaining access to the desired training model, task creators may also earn rewards for their contributions. However, these rewards are expected to be gradually phased out over time.
B. Training Node and Validator Selection
In this setup, each participant first stakes in the system to be eligible to perform task training or validation.
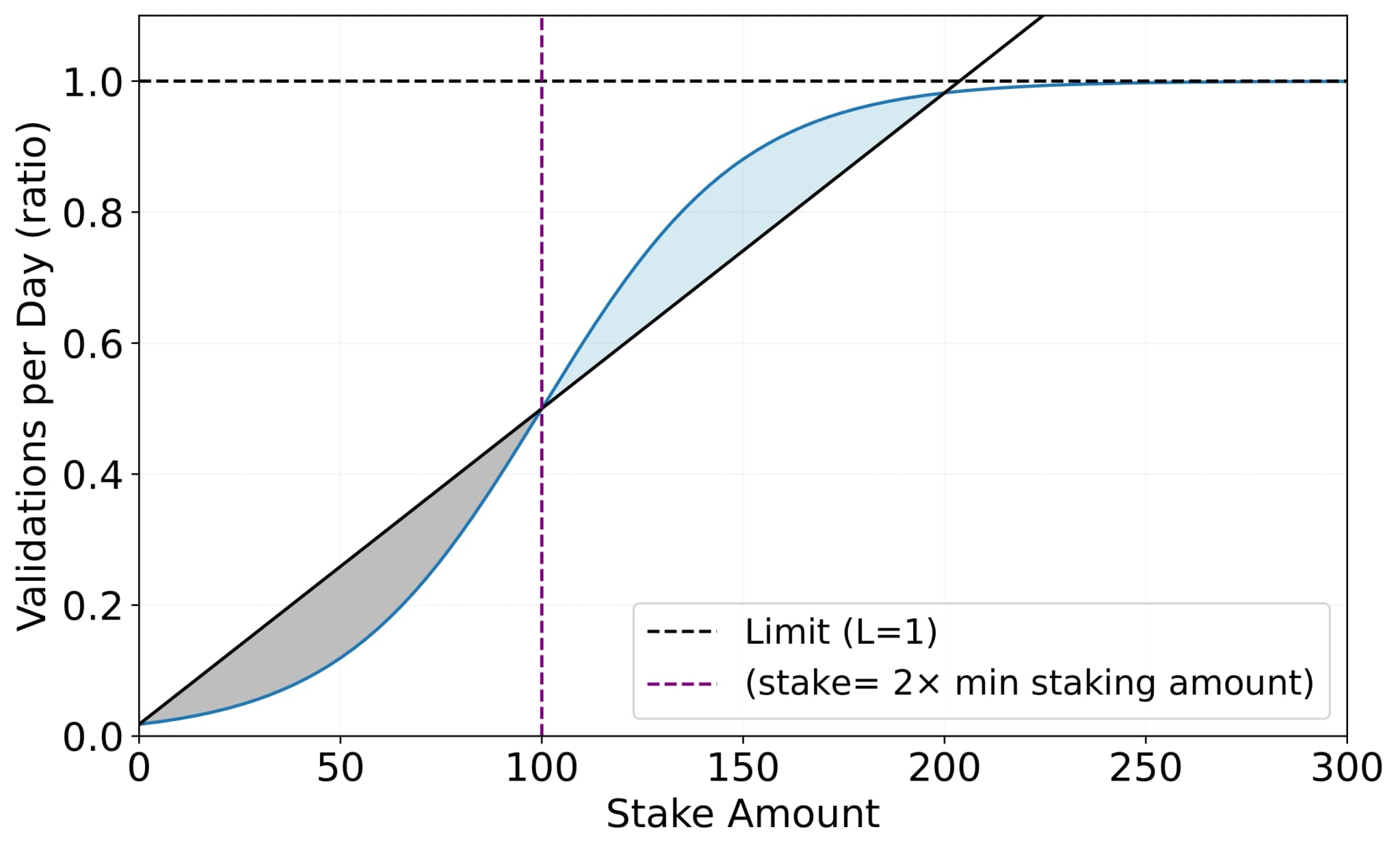
In practice, rate limiting is adopted to determine the number of times participants can access validation for a given task. As illustrated in Figure 4, the likelihood of a participant being selected to validate a task submission increases with their stake. However, the rate at which validation frequency increases relative to the staking amount tends to diminish as the staking amount grows.
C. Training in AI Arena
We consider the dataset held by the training node, , which contains locally sourced data samples, comprising feature set and label set , with each sample corresponding to a label . We define a predictive model , aiming to learn patterns within such that .
To quantify the prediction metric, accuracy as an example, the task trainer will introduce a loss function , assessing the discrepancy between predictions and actual labels . A generic expression for this function is:
where denotes the total sample count, and signifies a problem-specific loss function, e.g., mean squared error or cross-entropy loss.
The optimisation goal is to adjust the model parameters to minimise , typically through algorithms such as gradient descent:
where represents the learning rate, and the gradient of with respect to . Utilising the aggregated dataset , parameter is iteratively updated to reduce , consequently improving the model's predictive accuracy. This optimisation process is conducted over a predefined number of epochs , each epoch consisting of a complete pass through the entire dataset .
D. Validation in AI Arena
Consider a selected group of validators, denoted as , each equipped with the evaluation dataset from the task creator. This dataset consists of pairs , where represents the features of the -th sample, and is the corresponding true label.
The model, trained by designated training nodes, is denoted as . The primary objective of is to predict the label for each feature vector contained within .
To assess the performance of on , we use a general evaluation metric denoted by . Here, we exemplify with accuracy, which is calculated as follows:
Here, represents the indicator function that returns 1 if the predicted label matches the true label , and 0 otherwise. The function denotes the total number of samples within the evaluation dataset.
Each predicted label from the model is compared against its corresponding true label within the dataset . The calculated metric result (accuracy here) serves as a quantifiable measure of 's effectiveness at label prediction across the evaluation dataset.
E. Reward for Training Nodes in AI Arena
Within a single AI Arena task, the reward distribution between training nodes and validators is determined based on their relative stake amounts.
We assume there are submissions from training nodes, and validators , each with stakes . The stakes represent the validators' commitment and trust in the process, influencing the weight of their evaluations in the aggregated score.
Let the total daily reward allocated to a task be denoted as and the parameter controls the split rewards, defining the balance between fixed and stake-dependent reward components. Then, the total rewards for training nodes are:
- Each validator evaluates the models submitted by the training nodes, producing a score vector . These scores reflect the perceived accuracy, reliability, or performance of each model according to predefined criteria. The outlier scores proposed by malicious validators will be ignored by honest validators before taking into account in the following steps.
- The final score for each model from the training nodes is determined through a weighted aggregation:This means that the evaluations of validators with higher stakes have a larger impact on the final outcome.
- We then compute the following geometric series: in which denotes a given training node's rank amongst its peers in the same task, whereas represents the common ratio of the geometric series and is the number of training nodes in a given task. Participants in the FLock system, such as training nodes and validators, are required to contribute computing or storage resources to complete model training and validation in order to receive rewards. This means that the value of the
$FLOCKtoken will, at a minimum, correspond to the value of the resources consumed during these processes. - We finally compute the total rewards allocated for the training nodes as well as their delegators, which is based on the quality of their submission and their total amount of stake:where is a system parameter which determines the influence of the stake on the reward distribution, and the total stake amount of from the training node as well as its respective delegators.
- Consider as the reward ratio set by training node itself which determines the ratio of rewards shared between training node and its respective delegators. Consider also that a training node ' stake in the task is and stakes delegated to training node is , i.e. = + , where is a system parameter used to determine to the effective delegation amount, then the actual reward for training node is:
F. Reward for Validators in AI Arena
Similar to reward calculation for training nodes, the rewards for all validators in the same given AI Arena task is:
For each validator , we compute the distances between their score and the final aggregated score:
To fulfill the three criteria, we can employ a modified version of the Softmax Function:
- Purpose: Controls the sensitivity of the function to the distance . This distance measures the discrepancy between a validator's score and the aggregated score.
- Effect: A higher increases the function's sensitivity to score accuracy, emphasising the importance of precise evaluations.
- Selection Criteria: The choice of balances the need to penalise inaccuracies against the goal of rewarding nearly accurate evaluations.
- Purpose: Determines the influence of the stake amount on the reward distribution, thereby adjusting the weight given to validators' financial contributions.
- Effect: Allows for balancing between the importance of validators' financial commitment and their performance accuracy. A higher gives more weight to the stake amount in the reward calculation.
- Selection Criteria: Reflects the system's philosophy regarding the stake's importance relative to score accuracy. An of 0 means stake amounts are ignored, while a higher value increases their impact.
If the validator finishes multiple (i.e., ) validation tasks, then it reward ratio is:
If a validator’s stake in the task is , and is its accumulative stake by considering the total delegation amount on this validator, i.e., = + , in which is a system parameter used to determine the effective delegation amount. Then, the actual reward ratio for this validator is:
where is a system parameter which controls the rewards split between a given validator and its delegators.
G. Delegate Staking
Delegators may entrust their tokens to participants of their choosing to receive a passive investment income stream. The receivers can thus amplify their stake, influence, voting power, and rewards. These rewards are shared with the delegators, furthering cooperation. This extends participation to users who have tokens but lack the technical expertise to perform AI model training or validation.
Specifically, reward for the delegator depends on:
- The quality of the training nodes or validators selected for delegation.
- The amount of stake delegator has delegated.
Formally, consider as the effective delegation amount, reward for delegator who delegates to a training node can be calculated as:
whereas refers to the total reward distributed to the training node and delegator based on the quality of the training node's submission, is the stake amount from this given delegator, is the stake amount from training node and is the reward share ratio is the stake amount from training node and is the reward share ratio pre-determined by training node .
Similarly, reward for delegator who delegates to a validator can be calculated as:
In which is the Softmax function for validator mentioned above, whereas refers to the stake amount from a given delegator and is the stake amount from the validator itself.
In the future, FLock delegate staking has the option to be integrated with existing restaking platforms to attract users from a border blockchain community.
H. Various Validation Sets
To mitigate the lookup attacks from malicious training nodes, FLock validators adopt diverse validation datasets. Specifically, for a AI Arena task spanning days, the validation dataset used during the initial days differs from that of the final day. These distinct validation datasets are associated with two types of rewards: Reward A for the initial period and Reward B for the final day. This strategic approach enhances security by varying the data against which which training nodes are validated, thereby complicating any potential malicious attempts to exploit predictable validation scenarios.
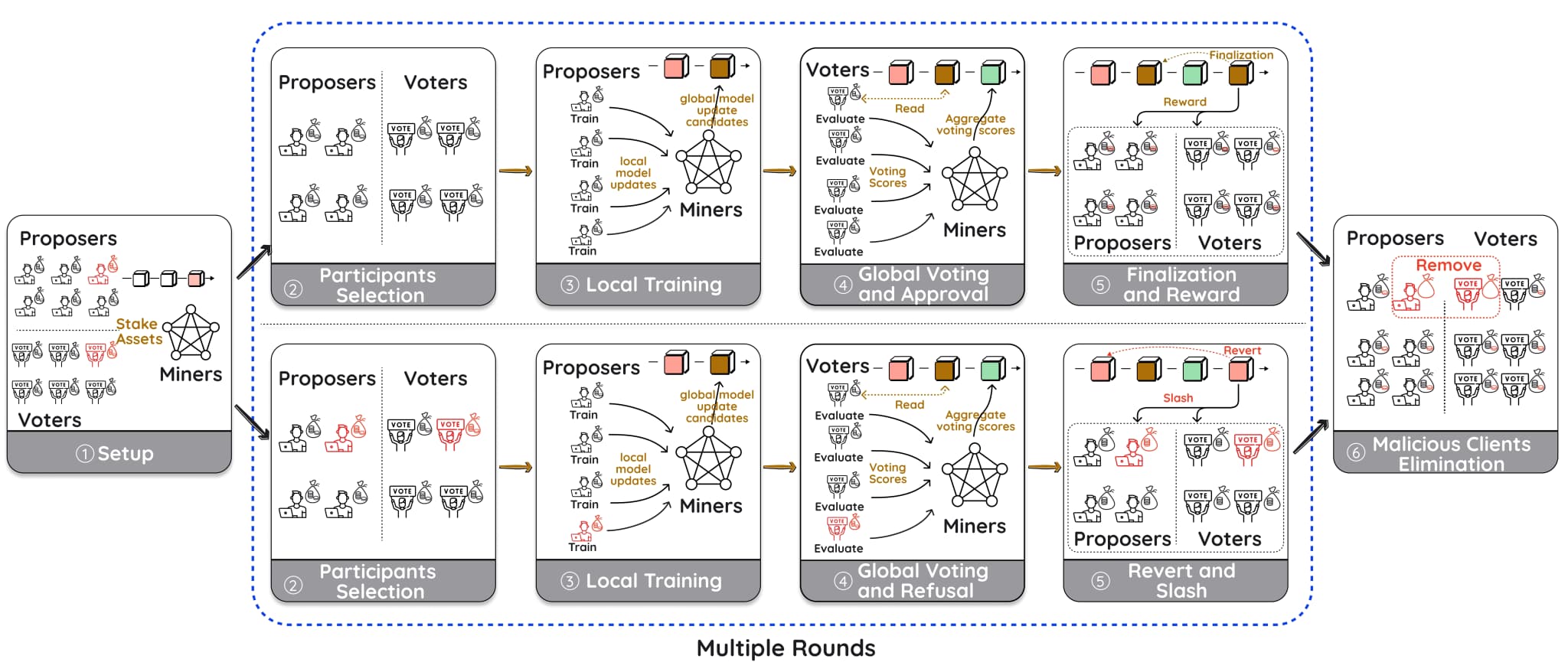
FIG. 5: Overview of the workflow of a FLock FL task, adopted from our previous work[14]. During each round, FL clients are randomly selected to act as proposers or voters. Their staked amount can be either rewarded or slashed based on the outcome of the majority voting results. Malicious clients will ultimately be removed from the FL system.
- For each AI Arena within the ecosystem, the rewards mechanism for training nodes is thoughtfully designed to comprise two distinct parts: Reward A and Reward B.
- Reward A provides a daily contingent reinforcement schedule, incentivizing participant engagement with AI Arena tasks through immediate gratification. This continuous reward mechanism fosters sustained participation by providing consistent feedback and reinforcing contributions.
- Reward B implements vesting, releasing tokens upon successful task completion within a predetermined lifespan. This incentivizes participants to both engage in tasks and ensure their timely and efficient completion. Vesting also functions as a quality control mechanism, promoting focused contributions aligned with project deadlines.
- Reward A of the AI Arena task is:
- Reward B of the AI Arena task is:
I. Example
We consider the rewards for the participants in task 1. We assume that:
- Daily total rewards for all AI Arena tasks for a given day is 309,157.68.
- There are 2 nodes and 3 validators in this given task.
- Nodes A and B stake 3,000 and 3,500
$FLOCKrespectively, while Validators A, B and C stake 3,000, 6,000 and 3,000 respectively. Node A also receives an additional 1,000$FLOCKfrom its delegators, which brings the (total stake including delegated stake) to be 4,000 for Node A. - For simplicity, we assume to be 0 in this example.
- We further assume to be 0.4, and to be 0.1.
- We consider the scores for Nodes A, B, Validators A, B and C are 0.501435, 0.498565, 0.472768, 0.280226 and 0.247006 respectively.
First, for this given task on Day 1, total rewards for all training nodes are:
We can then compute the rewards for Node A and its delegators. Consider , rewards for Node A (together with delegators) are:
Similarly, for Node B, its rewards together with its delegators are:
Given , the actual reward for Node A alone is:
As Node B does not have any delegator, so it will retain 100% of its rewards (i.e. 50,539).
As we assume is 0.1, Reward A is 10% of the daily rewards for training nodes, while 90% of the rewards (i.e. Reward B) will be locked until the end of task. Thus, Reward A and Reward B for Node A on Day 1 are 4,937.1 and 44,433.9 respectively, whereas those for Node B are 5,053.9 and 45,485.1 respectively.
As for validators, for the same task on Day 1, total rewards for all validators are:
Then, if we assume Validator A has a score of 0.472768, the the reward for validator A only is:
Similarly, on Day 1, rewards for Valdiator B (score = 0.280226, stake = 6,000) and Validator C (score = 0.247006, stake = 3,000) are 87,834 and 38,703 respectively.
As for Delegator A who delegates 1,000 to Node A, its rewards on Day 1 are calculated as such:
The reward distribution among the participants in task 1 during the 5 days is shown in Table II.
| Total | Training Nodes | Delegators | Validators | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Training Node A | Training Node B | Delegator A | Val. A | Val. B | Val. C | ||||
| Reward A | Reward B | Reward A | Reward B | ||||||
| Day 1 | 309,157.68 | 4,937.1 | 44,433.9 | 5,053.9 | 45,485.1 | 8,712.6 | 73,997 | 87,834 | 38,703 |
| Day 2 | 309,157.68 | 4,937.1 | 44,433.9 | 5,053.9 | 45,485.1 | 8,712.6 | 73,997 | 87,834 | 38,703 |
| Day 3 | 309,157.68 | 4,937.1 | 44,433.9 | 5,053.9 | 45,485.1 | 8,712.6 | 73,997 | 87,834 | 38,703 |
| Day 4 | 309,157.68 | 4,937.1 | 44,433.9 | 5,053.9 | 45,485.1 | 8,712.6 | 73,997 | 87,834 | 38,703 |
| Day 5 | 309,157.68 | 4,937.1 | 44,433.9 | 5,053.9 | 45,485.1 | 8,712.6 | 73,997 | 87,834 | 38,703 |
VI. FLock Consensus in FL Alliance
Figure 5 depicts the workflow of a FL Alliance task in FLock. As shown in our work in leveraging blockchain to defend against poisoning attacks in FL Alliance[14], FLock adopts a distributed voting and a reward-and-slash mechanism to construct secure FL Alliance systems.
A. Task Creators
Similar to task creation in AI Arena, an FL Alliance task creator must satisfy predefined criteria. Only FL Alliance tasks verified by the FLock DAO will be eligible for rewards from the daily emissions. Otherwise, the FL Alliance task creator must self-fund the reward pool using their own $FLOCK.
Algorithm 1 FLock Federated Learning
B. Random Role Selection
Consider a FL Alliance task involving participants, denoted as . To participate in the training process, each participant needs to stake a specified quantity of coins. Upon formally joining the training task, each participant's local dataset is randomly partitioned into a training set and a test set , which will not be shared with other participants at any time. At the beginning of each round in the FL Alliance task, participants are randomly assigned roles as either a proposer () or a voter () through an on-chain random function. Subsequently, a model initialised or pre-trained model downloaded from AI Arena by one of the proposers is chosen at random temporarily to serve as the pioneering global model. The selected model's weights or gradients are then distributed to all participants, ensuring a unified starting point for local models. Proposers are responsible for training their local models using their own data and subsequently sharing the updated model weights or gradients with all participants. Voters, on the other hand, aggregate these updates from proposers. They then proceed to validate the aggregated model updates, resulting in the generation of a validation score.
C. FL Alliance Training
At the start of round , proposers initially download the global model, denoted as , which was finalised in the previous round . Using the local training dataset , proposers then proceed to update the model through epochs of local training. Then the updated model of the current round will be uploaded to the voters for evaluation.
Algorithm 2 Reward-and-slash design for FL clients.
D. FL Alliance Aggregation
Upon the completion of task training during round , the voter gathers the local models from proposers. These models are then aggregated into the latest global model using a weighted averaging approach, as described below:
Here, the weight is defined as , with indicating the number of local training data samples for each proposer , and is the total number of training data samples across all proposers .
E. FL Alliance Validation and Voting
- After the model aggregation process is finalised, the voter proceeds to evaluate the aggregated model utilising their own local testing datasets . This evaluation phase involves the computation of a local validation score, , which functions as a criterion for assessing the model's performance. These individual validation scores are then submitted to a smart contract for aggregation. Following the aggregation, the aggregated score is compared with the previous round's score, , to assess progress or decline in model performance. The smart contract then determines the next steps for the aggregated model based on these scores: advancement to the next phase for satisfactory performance improvement, or a return to the preceding validated model to begin a new cycle of training, aggregation and evaluation, if progress is deemed insufficient.Here, is a hyperparameter within the range , designated to tolerate the permissible margin of performance decline across successive rounds.
- After receiving all reported voting results , from the validators, the aggregator will calculate the aggregated voting result via the following formula:For each round , the finalised aggregated global model update is determined by the aggregated voting result:
F. FL Alliance Rewards for Participants
The aggregated voting result will also determine the rewards distribution for participants in a FL Alliance task
- Rewards and Penalties for Proposers/Training Nodes: As shown in Algorithm 2, in any given round , should be non-negative, all training nodes selected for that round will receive rewards. Conversely, a negative aggregate vote will result in penalties for these nodes.
- Rewards and Penalties for Voters/Validators: As shown in Algorithm 2, for round , then validators who issued a positive vote will be rewarded, while others will face penalties. Conversely, should the aggregate vote be negative, validators who aligned with this outcome are rewarded, whereas those who did not will be penalised.
G. Example
As illustrated in Figure 6(D), taken from our previous work[14], proper configuration of the slashing and reward mechanisms enables the expulsion of malicious FL participants from the system, while incentivising honest behaviour.
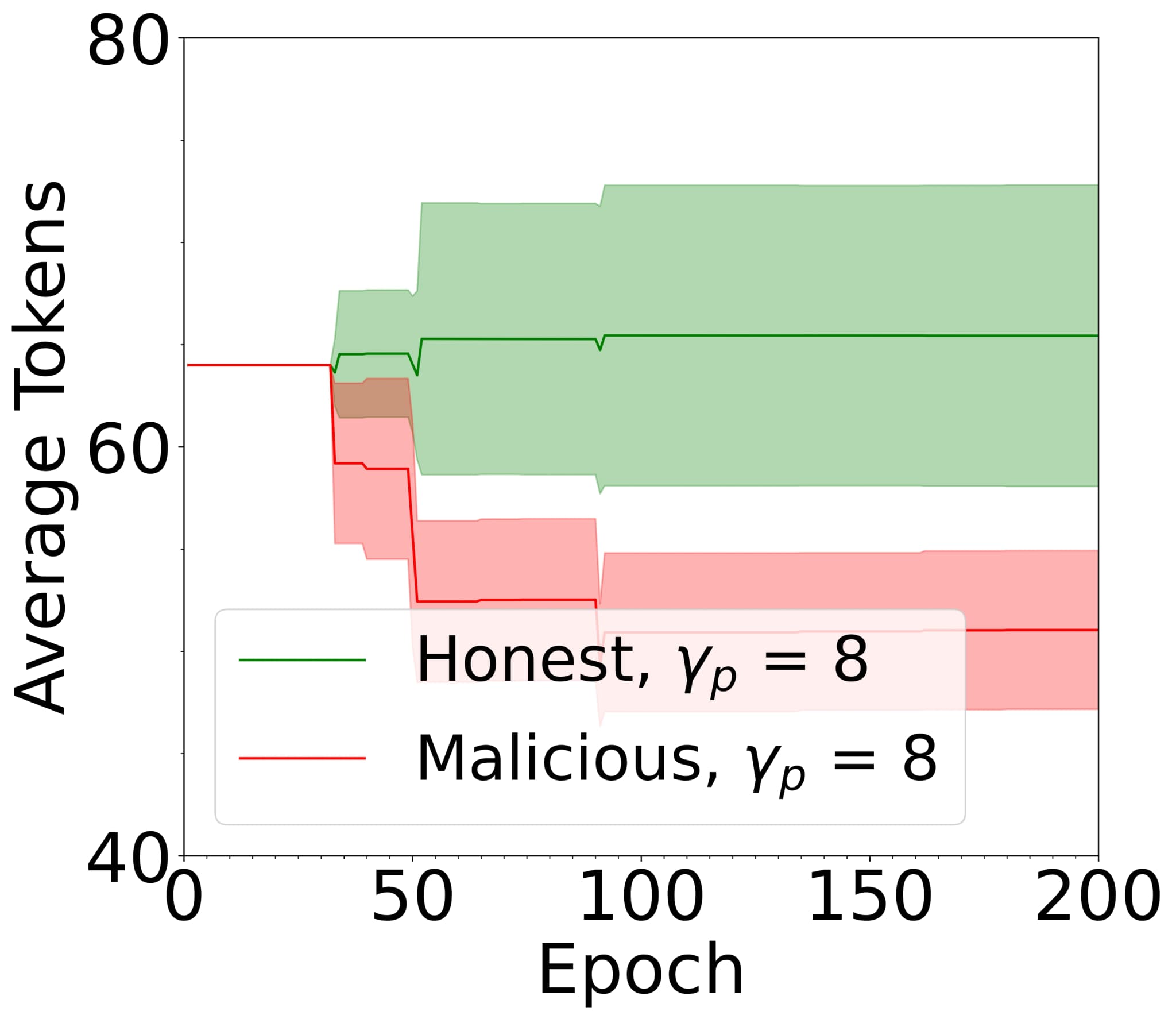
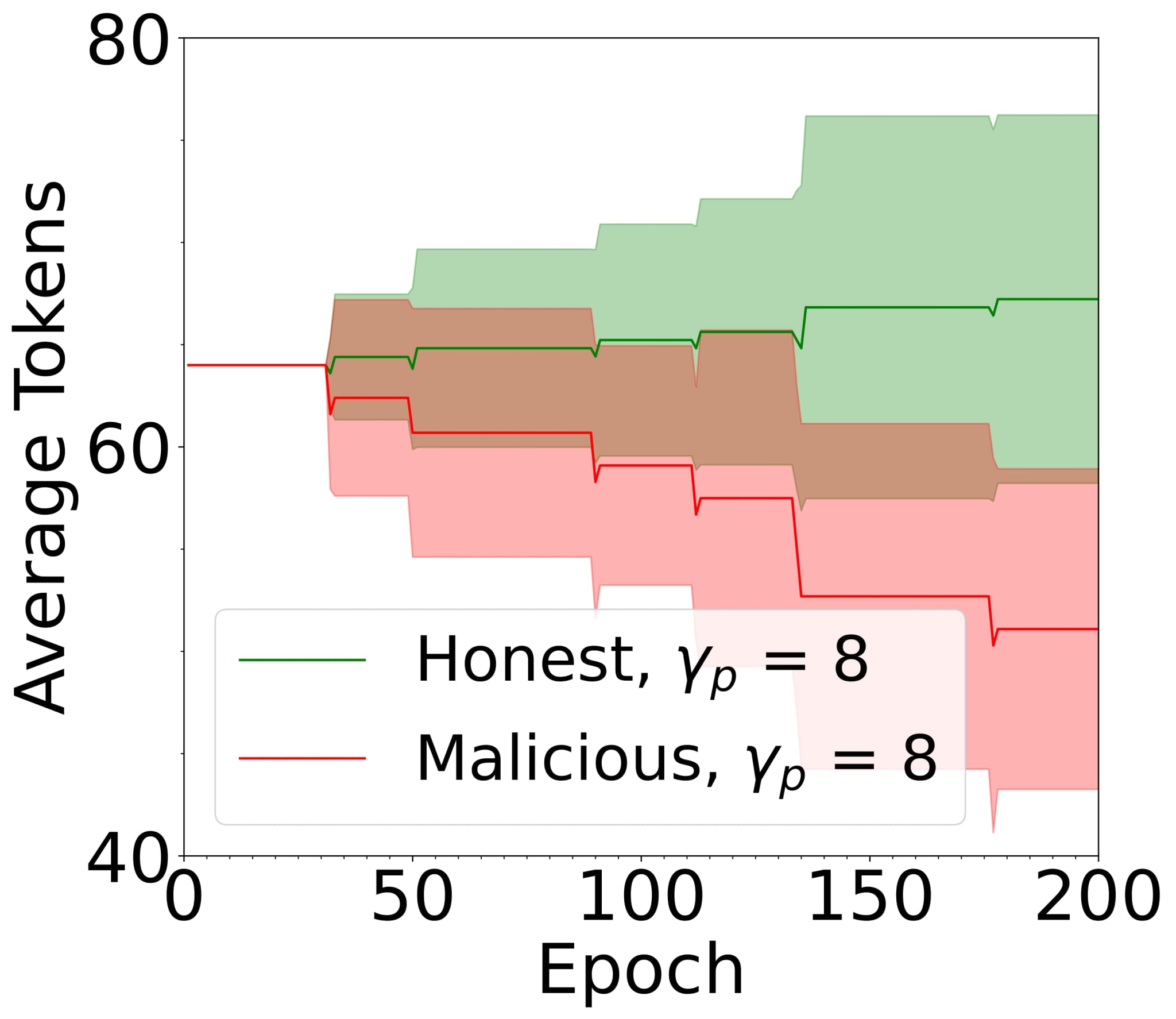
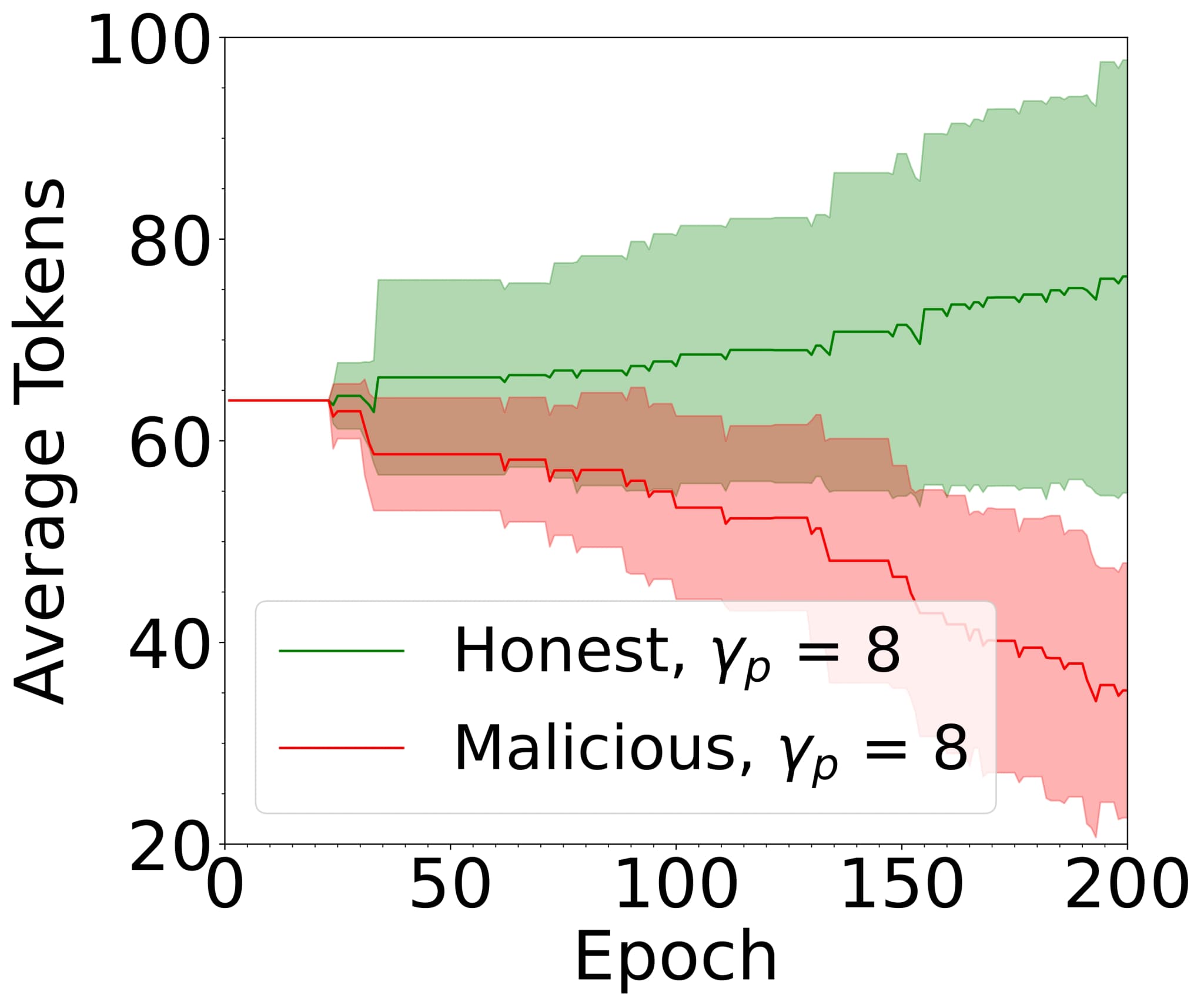
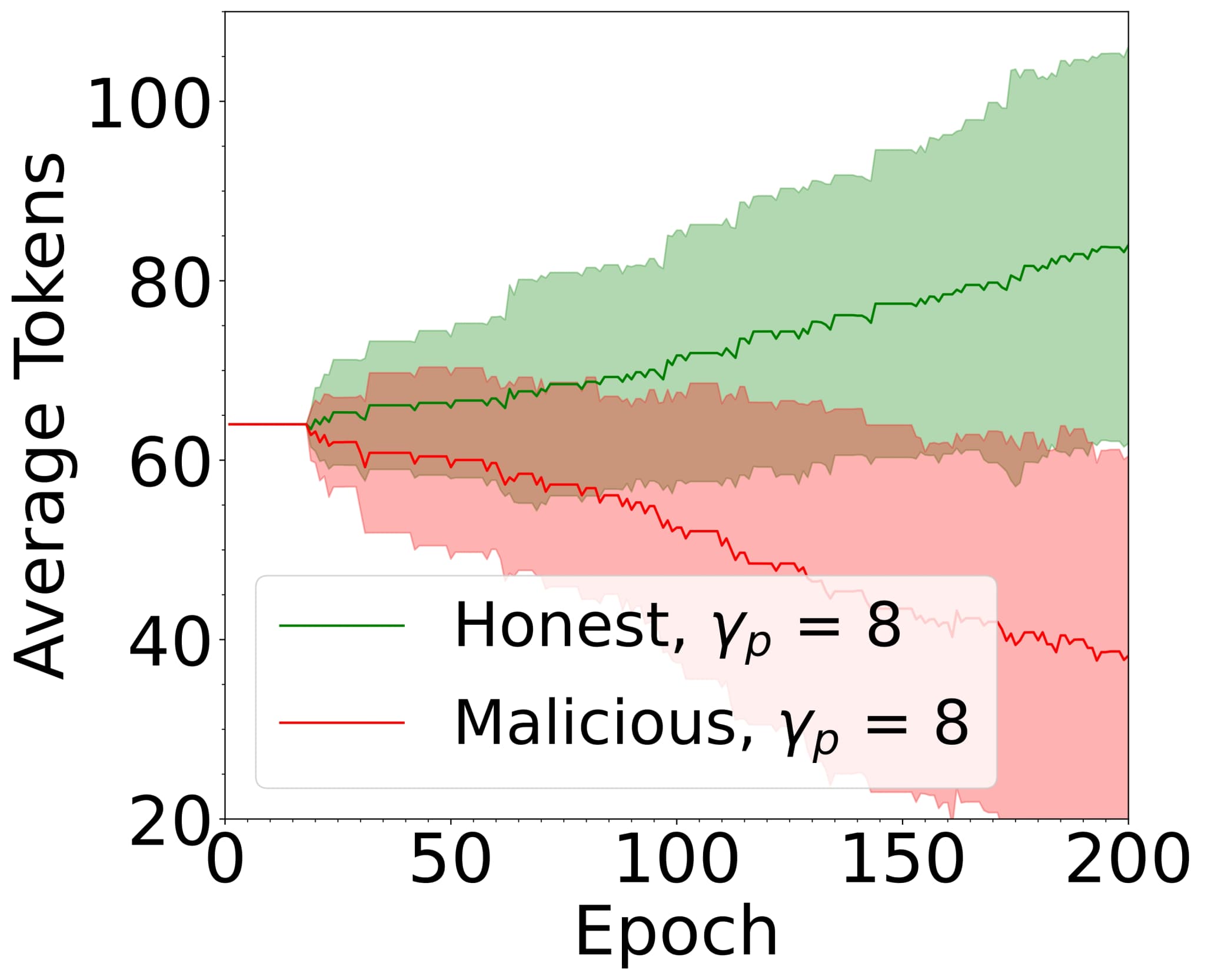
FIG. 6: Example: FL system with reward and slash mechanism under different values of the ratio of malicious clients , taken from[14]. The average balance of honest clients increases, while the average balance of malicious clients decreases over time.
H. FL Alliance Improvement: ZKPs-based FL
FLock also adopts advanced techniques such as Zero-knowledge proof (ZKP)[16],[17] to construct secure decentralised AI training systems.
ZKPs for FL Alliance Aggregation: As demonstrated in our prior study, FLock incorporates ZKP to address the issues arising from the centralisation of the FL Alliance aggregator/server, as detailed in our earlier research[18]. Our FL system, which can be underpinned by both blockchain technology and ZKPs and function in the following manner:
- Setup Phase: Each participant, comprising clients and an aggregator, generates their unique private/public key pairs. These pairs are directly associated with their respective blockchain addresses.
- Client Selection Phase: At the beginning of each epoch, a subset of clients is selected from the total by using Verifiable Random Functions.
- Local Computation Phase: The selected clients start local model training to derive their individual model updates . Utilising the Pedersen commitment, each client encrypts their update as , where and are predefined public parameters and is a randomly generated number by the client. Following encryption, clients authenticate these updates using their private keys to produce a signature and subsequently transmit the compilation of their local model update, the generated random number, the encrypted update, and the signature to the aggregator.
- Aggregation and ZKP Generation Phase: The aggregator aggregates the incoming local updates to form a unified global model update . It also calculates the collective encrypted value of this global update as and signs this encrypted value to produce a signature . Utilizing zkSnarks, the aggregator issues a proof to validate the accuracy and authenticity of the aggregation process, based on the provided statement and witness, ensuring the integrity of both the individual updates and the aggregate model. Specifically, the aggregator then leverages zkSnark to issue a proof for the following statement and witness:where the corresponding circuit if and only if:
- Global Model and Proof Dissemination Phase: The aggregator distributes the global model update and its encryption back to the clients. Concurrently, it broadcasts the validity proof along with the encrypted global model update to the block proposers.
- Blockchain Verification Phase: Upon receiving the proof and the encrypted global model update from the aggregator, block proposers verify . If deemed valid, the hash of is inscribed onto the blockchain, cementing the update's correctness.
- Blockchain Consultation Phase: As a new epoch initiates, the next cohort of selected clients peruses the blockchain to verify the inclusion of . Upon successful validation, they proceed with their local training, guided by the insights gleaned from the aggregated global model update .
VII. FLock Governance
FLock token holders are entitled to engage in the system's democratised governance through a DAO. To participate in governance, token holders typically need to lock their tokens in a smart contract. Each token can represent a vote, aligning the distribution of power proportional to users' stake.
Users can propose, debate, and vote on various aspects of development and management, from technical updates and protocol modifications to treasury management and community initiatives.
- Proposing: The FLock community actively shapes the protocol's future through a proposal system for all token holders. Proposals can range from addressing technical issues like bug fixes and algorithm optimization to driving wider community impact, such as allocating treasury funds for research or launching educational programs.
- Debating: Proposed ideas are then open for discussion and critique within the FLock community. Token holders can engage in forums, discussions, and possibly even direct communication with developers to analyze the merits and potential consequences of each proposal. This debate fosters transparency and ensures that decisions are well-informed and considered from multiple perspectives.
- Voting: Once a proposal has been sufficiently debated, token holders cast their votes to decide its fate. The voting system likely incorporates mechanisms like weighted voting (where larger holdings carry more weight) or quadratic voting (which incentivizes thoughtful contributions and discourages manipulation) to ensure fair representation.
The statement emphasizes that FLock’s governance model allows for continuous adaptation as the platform and the decentralized AI landscape evolve:
- Policy Adaptation: As new challenges and opportunities arise, token holders can use the voting system to modify existing policies or create entirely new ones. This ensures that FLock remains relevant and responsive to the changing needs of its community and the broader AI ecosystem.
- Feature Implementation: Proposals for implementing new features can be put forward and voted on, allowing the FLock platform to grow and evolve based on user demand and feedback. This fosters innovation and keeps FLock at the forefront of decentralized AI development.
- Responding to Challenges: The ability to quickly adapt policies and implement changes allows FLock to effectively respond to unforeseen challenges like security vulnerabilities, regulatory shifts, or market fluctuations.
As FLock and decentralised AI landscape mature, token holders can adapt policies, implement new features, and re- spond to emerging challenges.
VIII. FLock Applications
The FLock system can be used to construct centralised AI, which have been proven to applied in the following cases.
A. Decentralised AI for LLMs
- Pre-training of LLMs: FLock facilitates the pre-training of LLMs by leveraging a decentralized network whereby members can contribute computational resources and diverse data sets. This unlocks proprietary data that would otherwise remain inaccessible or unused in traditional, centralized open-source development. Diverse datasets ensure LLM versatility and a broader representation of linguistic and cultural nuances, as well as community-defined values for LLMs.
- Fine-tuning of LLMs: Fine-tuning involves adapting a pre-trained model to perform specific tasks or improve its accuracy on particular types of data. FLock supports fine-tuning in several ways:
- Fine-tuning for Financial Transactions: LLMs can be fine-tuned to act as intelligent agents for cryptocurrency transactions. Capabilities include transfers, swaps, and bridging between different cryptocurrencies. FLock's collaborations with platforms such as Morpheus Network and 0xscope can facilitate hosting these AI models, ensuring that they are accessible and operational for the community. This enables secure and efficient AI-driven financial transactions.
- Fine-tuning for AI Companions: AI models can be fine-tuned to interact with users in more personalized and engaging ways, similar to those on platforms like Character.ai. FLock can host these sophisticated AI companions, enhancing user experience through more natural and context-aware interactions.
B. Decentralised AI for Stable Diffusion Models
The FLock system can be used to fine-tune Stable Diffusion text-to-image models. One critical component of this process involves Low-Rank Adaptation (LoRA)[19], which modifies certain parameters within the model's architecture to make it more adaptable to specific tasks without extensive retraining.
- Fine-tuning LoRA: LoRA is designed to adapt pre-trained models by introducing trainable low-rank matrices into the architecture. This technique allows for efficient adaptation with minimal additional computational cost and a smaller number of trainable parameters. In the context of FLock and Stable Diffusion Models, applying LoRA is particularly advantageous for several reasons:
- Community-Driven Enhancements: By decentralizing the fine-tuning process, FLock broadens participation in contributing specific knowledge and preferences. Artists, designers, and other creatives can input unique styles or features they wish to see enhanced, improving output quality and ensuring that it serves a wider array of cultural contexts and artistic expressions.
- Scalability and Accessibility: Fine-tuning with LoRA can be scaled across multiple nodes, facilitating more widespread and continuously iterative improvements.
- Use Case Expansion: By fine-tuning Stable Diffusion Models with LoRA, FLock can cater to specific industries or niches. For example, the model could be fine-tuned to generate medical illustrations for educational purposes, architectural visualizations for real estate, or unique art styles for digital media.
C. Decentralised AI for Linear Regression Models
Linear regression models[20] are fundamental tools in statistical analysis and predictive modeling, widely used for their simplicity and effectiveness in understanding relationships between variables. FLock applies these principles in a decentralised setting to address specific healthcare challenges, such as diabetes management.
Diabetes management presents a critical area where linear regression can be effectively utilised to predict patient outcomes based on various inputs such as blood sugar levels, diet, exercise, and medication adherence. FL Alliance facilitates the development of these predictive models with decentralised data sources in a way that respects patient data protection.
- Data Protection and Security: FLock allows multiple healthcare providers to collaborate in the model training process without actually sharing the data. This method is crucial for complying with stringent health data protection regulations such as HIPAA in the U.S. Each participant (e.g., hospitals, and clinics) retains control over their data, which is used to compute model updates locally. These updates are then aggregated to improve a shared model without exposing individual patient data.
- Enhanced Model Accuracy and Reliability: By integrating data from a diverse range of demographics and geographical locations, FLock can help develop more accurate and generalised linear regression models for diabetes management. This diversity is especially important in healthcare, where patient populations can vary significantly, affecting the reliability of predictive models.
- Collaborative Innovation: Different healthcare entities contribute to a common goal, accelerating innovation and leading to the discovery of novel insights into diabetes management and treatment strategies.
IX. Conclusion
FLock provides solutions to build decentralised AI through AI Arena, FL Alliance, and AI Marketplace. FLock dismantles obstacles that hinder participation in AI systems, enabling de- velopers to contribute models, data, or computational resources in a flexible, modular fashion. FLock fosters the creation of a diverse array of models, meticulously crafted by and expressly for the communities they serve in AI models.
References
- [1] S. Nakamoto, “Bitcoin: A peer-to-peer electronic cash system,” 2008.
- [2] G. Wood, “Ethereum: A secure decentralised generalised transaction ledger,” Ethereum project yellow paper, vol. 151, pp. 1–32, 2014.
- [3] S. Werner, D. Perez, L. Gudgeon, A. Klages-Mundt, D. Harz, and W. Knottenbelt, “Sok: Decentralized finance (defi),” in Proceedings of the 4th ACM Conference on Advances in Financial Technologies, 2022.
- [4] P. Bellavista, L. Foschini, and A. Mora, “Decentralised learning in feder- ated deployment environments: A system-level survey,” ACM Computing Surveys (CSUR), vol. 54, no. 1, pp. 1–38, 2021.
- [5] T. Wu, S. He, J. Liu, S. Sun, K. Liu, Q.-L. Han, and Y. Tang, “A brief overview of chatgpt: The history, status quo and potential future development,” IEEE/CAA Journal of Automatica Sinica, 2023.
- [6] Y. Shen, K. Song, X. Tan, D. Li, W. Lu, and Y. Zhuang, “Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [7] R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chen et al., “Palm 2 technical report,” arXiv preprint arXiv:2305.10403, 2023.
- [8] “Why google’s ai tool was slammed for showing images of people of colour,” available at: https://www.aljazeera.com/news/2024/3/9/why-g oogle-gemini-wont-show-you-white-people.
- [9] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
- [10] NIST, “There’s more to ai bias than biased data, nist report highlights,” available at: https://www.nist.gov/news-events/news/2022/03/theres-m ore-ai-bias-biased-data-nist-report-highlights.
- [11] IBM, “Shedding light on ai bias with real world examples,” available at: https://www.ibm.com/blog/shedding-light-on-ai-bias-with-real-wor ld-examples/.
- [12] “When ai gets it wrong: Addressing ai hallucinations and bias,” available at: https://mitsloanedtech.mit.edu/ai/basics/addressing-ai-hallucination s-and-bias/.
- [13] N. Dong, J. Sun, Z. Wang, S. Zhang, and S. Zheng, “FLock: Defending malicious behaviors in federated learning with blockchain,” NeurIPS 2022 Workshops on Decentralization and Trustworthy Machine Learn- ing in Web3: Methodologies, Platforms, and Applications. Runner-up Award., 2022.
- [14] N. Dong, Z. Wang, J. Sun, M. Kampffmeyer, W. Knottenbelt, and E. Xing, “Defending against poisoning attacks in federated learning with blockchain,” IEEE Transactions on Artificial Intelligence, 2024, https://arxiv.org/pdf/2307.00543.pdf.
- [15] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial intelligence and statistics. PMLR, 2017.
- [16] E. B. Sasson, A. Chiesa, C. Garman, M. Green, I. Miers, E. Tromer, and M. Virza, “Zerocash: Decentralized anonymous payments from bitcoin,” in IEEE Symposium on Security and Privacy, 2014.
- [17] J. Groth, “On the size of pairing-based non-interactive arguments,” in Advances in Cryptology–EUROCRYPT, 2016.
- [18] Z. Wang, N. Dong, J. Sun, W. Knottenbelt, and Y. Guo, “zkfl: Zero- knowledge proof-based gradient aggregation for federated learning,” IEEE Transactions on Big Data, 2024.
- [19] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021.
- [20] D. C. Montgomery, E. A. Peck, and G. G. Vining, Introduction to linear regression analysis. John Wiley & Sons, 2021.